Die Diskussion um die Konkurrenz zwischen stationärem Handel und Online-Handel bestimmt derzeit die Wahrnehmung vieler ökonomisch interessierter Beobachter. Doch ohne hier allzu „predictive“ aufzutreten, zeichnet sich ab, dass letztlich nur wirklich große Filialisten – wenn überhaupt – den Wettbewerb mit Online überleben werden. Dies wahrscheinlich auch nur in Bereichen in denen Haptik, „anprobieren“ oder Lifestyle Shoppen in der Öffentlichkeit („Sehen und gesehen werden“) eine Rolle spielt.
Aggressiver Wettbewerb online vs. online
Viel schärfer als der Wettbewerb zwischen Offline und Online, ist der aggressive Wettbewerb online vs. online. Durch die, im Vergleich zu real existieren Warenhäusern, niedrigeren Eingangshürden bei der Eröffnung eines online Versandhandels oder Teilnahme an einem Marketplace als Anbieter, stieg die Anzahl der Marktteilnehmer in den letzten Jahren exorbitant an.
So wurde es für traditionelle, wenig ausdifferenzierte Anbieter zunehmend schwieriger, sich in diesem Markt zu behaupten. Marketing, technisches Marketing, SEO und SEA müssen stark gepimpt werden und die gesamte Lieferkette muss auf hohe Effizienz getrimmt werden. Letztlich überlagert Amazon alles, und man braucht schon ein innovatives Tool- und Mindest, um im Umfeld Online-Handel bestehen zu können.
Unique Selling Point
Ein recht neuer Ansatz ist „Predicitive Analytics“. Er bietet Möglichkeiten, das Kauf- und Surf-Verhalten sowie die Reaktion von Kunden auf bestimmte Angebote vorherzusagen. Damit kann ein Unique Selling Point evtl. mit hyperpersonalisierten Preisen und Produkten entwickelt werden, der tatsächlich einen kleinen Vorsprung bieten kann. In einem stark umkämpften Markt kann das ein echter Vorteil sein.
„Big Data“, „Data Lake“, „Data Warehouse“ etc. – wird in diesem Text nicht weiter differenziert. Es geht einfach darum, dass man natürlich eine Datenquelle benötigt, um mit Daten zu arbeiten, diese banale Erkenntnis soll zunächst mal ausreichen.
Eine Beziehungskiste
Das besondere an „Predictve Analytics“ ist, dass in diesem Verfahren letztlich Metadaten ausgewertet werden, welche erst zum Vorschein kommen, wenn die vorhandenen Daten in eine Beziehung zueinander gesetzt werden. Es geht also nicht um einen einzelnen Datensatz, oder einen Vergleich von Datensätzen – es geht um die vielfältigen Beziehungen zwischen Daten. Diese Informationen sind häufig bei der ursprünglichen Datenerhebung überhaupt nicht mitgedacht worden.
Beispiel (Klassiker): Bei der Erfassung von Kassenbons in einem Warenhaus wird gleichsam unbeabsichtigt mit erfasst, welche Produkte gemeinsam mit anderen Produkten in der Einkaufstasche des Kunden landen. Hier könnte man Produktbundles anbieten und so schneller einen höheren Abverkauf erreichen, bzw. auch Bundlepreise bieten. Weiß man dies über einen wiederkehrenden Kunden genau, ist man schon im Bereich der predictive Hyperpersonalisierung. Dies kann man durch alle Sales-Kanäle runterrocken. Newsletter nicht vergessen!
Daten Bergleute
Ja aber? Hä? Ich mein, wie sucht man nach Informationen in Daten, wenn man gar nicht weiß, wonach man suchen muss? Jetzt schlägt die Stunde des „Data Minings“. Dabei handelt es sich um einen zusammenfassenden Begriff für Algorithmen, die nach bisher unbekannten Beziehungen zwischen Daten suchen. Das ist zunächst schon einiges: Wir bekommen ein Angebot an Datenbeziehungen und eine technische Aussage darüber, wie stark die Beziehungen zwischen verschiedenen Daten sind. Für den Konzeptionierer bleibt dann, daraus einen Business Case zu generieren, der die Abverkäufe pusht, das Kundenbeziehungsmanagement verbessert, vielleicht faule Eier aussortiert etc. etc. etc. Bis heute sind vor allem Kundenbeziehungspflege, Cross- und Upselling, sowie technisches Recommender Marketing der Burner.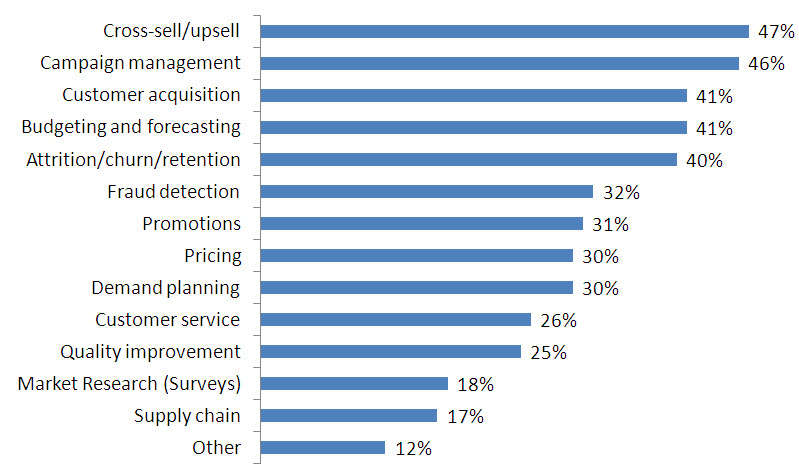
Algorithmisches Recommender Marketing und der Katzenfaktor
Das algorithmische Recommender Marketing ist hierbei nicht zu verwechseln mit Empfehlungsmarketing (Wer das kauft hat, auch das gekauft…, 4 Werbegeschenke in der Hoffnung, dass der Beschenkte sie weiter verteilt…). Denn das ist traditionelles Marketing mit:
- hohen Streuverlusten
- schlechter Messbarkeit
- geringem Personalisierungsgrad
In der zeitgemäßen Form des Empfehlungsmarketings geht es vor allem darum, mit Hilfe von Predictive Analytics zu erreichen, dass ein Kunde einem anderen Kunden etwas empfiehlt, aber nur dann, wenn die beiden Kunden auf vielen Ebenen gut zusammenpassen.
Dies kann man z.B. im Online-Handel anhand von Profilen, Community Aktivitäten, Supportanfragen etc ableiten. Weiter muss dies automatisiert erfolgen, um effizienter zu sein. Beispiel wäre also ungefähr: Bei einem Kauf erstellt ein Programm ein Profil und kategorisiert/verschlagwortet den Kunden. Dann wird aus einer bereits erfolgten Kundenkategorisierung ein möglichst passgenaues anderes Profil gesucht und seine Käufe analysiert. Fußend auf dieser Analyse kann nun ein Produktbundel geformt werden, was scheinbar durch einen anderen Kunden (Harry S. ist auch Dortmund Fan und liebt Katzen), dem gerade kaufenden Kunden empfohlen wird. Das setzt natürlich zunächst voraus, Kundenaktivitäten zu tracken, zu sammeln und dann ins Data Mining einzusteigen.
Wenn man das Ganze auf seinen abstrakten Kern eindampft, haben wir es natürlich mit statistischen Verfahren zu tun.
Erklärungsmodell vs. Vorhersagemodell
Erklärungsmodelle sollen Zusammenhänge zwischen einzelnen Variablen belegen. Damit muss vor der Erstellung solcher Modelle eine Hypothese entwickelt werden, die es anhand der vorhandenen Daten zu belegen gilt. Datengrundlage für diese Modelle sind zumeist Beobachtungsdaten aus der Vergangenheit. Ziel eines Erklärungsmodells ist es, eine Aussage über die Wirkzusammenhänge eben dieser Datengrundlage zu machen. Wenn es zwanzig Jahre nicht regnet, ist von einer Dürre auszugehen, also werden wir in Erntedaten einen Rückgang bei Weizen, Hafer etc. feststellen. In den Wetterdaten werden wir die niedrigen Niederschlagswerte finden – damit ist die Preissteigerung beim Weizen erklärt, wir können aber daraus keine Aussagen über zukünftige Entwicklungen einzelner Variablen ableiten.
Vorhersagemodelle sind statistische Modelle, die aus empirisch belegten Daten, Aussagen über die zukünftige Entwicklung verschiedener Ausgabevariablen machen. Und die, wenn man noch einen Schritt weitergehen möchte, zumindest theoretisch Aussagen dazu treffen können, was passiert, wenn die angesprochene empirische Basis sich verändert. Hier müssen also vor der Modellerstellung keine Hypothesen über Ein- und Ausgangsvariablen getroffen werden, die es zu beweisen gilt. Die Veränderbarkeit der empirischen Ausgangslage wird als Erfahrungsschatz hinterlegt, mit dem Ziel die Aussagen über die zu erwartenden Variablen zu präzisieren – dies leitet dann schon in den Bereich des maschinellen Lernens über.
Beispiele für Vorhersagemodelle sind:
-
- Online-Filmbewertungen IMDB nutzen, um die Einkaufsmenge dieser oder jener DVD mit zu bestimmen
- Algorithmisches Recommender Marketing
Im nächsten Teil (soweit er denn tatsächlich erscheint; wir rechnen zumindest damit) schauen wir uns die Modellierung von Datenmodellen an.